Your form has been submitted. We'll contact you in 24 hours.
Close
Home/Blog/How to use API to access dynamic residential proxy site for e-commerce website data crawling?
How to use API to access dynamic residential proxy site for e-commerce website data crawling?
PYPROXY·Apr 10, 2025
Data scraping has become a critical tool for e-commerce businesses to gain insights into competitors, market trends, and customer behavior. However, scraping data from dynamic websites presents unique challenges. Dynamic residential proxy sites can be an effective solution to these challenges, allowing businesses to scrape data from e-commerce websites without being blocked or detected. In this article, we will explore how to use APIs to access dynamic residential proxy sites for efficient e-commerce website data scraping, discussing the methodology, benefits, and technical aspects involved.
Understanding the Basics of Web Scraping
Web scraping refers to the automated process of extracting data from websites. It involves sending requests to web pages, retrieving their content, and parsing it into structured data. This process can be used for various purposes, such as monitoring competitors, gathering product data, analyzing customer feedback, and conducting market research.
However, dynamic websites (those that load content via JavaScript or AJAX) present a challenge for traditional scraping methods, which rely on static HTML content. In such cases, dynamic proxies and APIs become essential for bypassing restrictions and accessing the desired data.
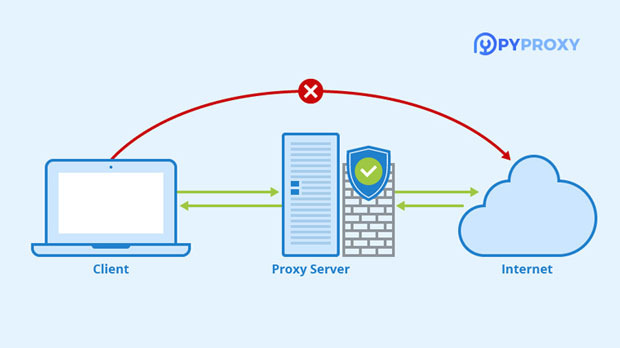
Dynamic residential proxies play a key role in web scraping by masking the scraper’s identity and making it appear as though the requests are coming from real users. These proxies use IP addresses from real residential locations, making it much harder for websites to detect or block them.
Unlike datacenter proxies, which are often flagged by websites due to their repetitive nature, residential proxies blend seamlessly with regular user traffic. This enables scrapers to bypass IP blocking mechanisms and continue extracting data without interruptions.
Benefits of Using Dynamic Residential Proxies for E-commerce Data Scraping
1. Bypassing Geographical Restrictions
Many e-commerce websites display region-specific content or prices based on the IP address of the user. Using dynamic residential proxies, businesses can access websites from various locations, ensuring they see the exact data intended for specific regions.
2. Avoiding IP Blocking and Rate Limiting
Websites may block or throttle requests from the same IP address if too many requests are made in a short period. Dynamic residential proxies rotate IPs continuously, preventing such blocks and ensuring that scraping activities remain undetected.
3. Maintaining Anonymity
When scraping data, anonymity is crucial to avoid detection. Dynamic residential proxies provide enhanced anonymity by using real, non-dedicated IP addresses, making it harder for websites to associate scraping activities with a single source.
How to Access Dynamic Residential Proxy Sites with API for Data Scraping
Using APIs to access dynamic residential proxy sites simplifies the process of data scraping by providing developers with ready-to-use solutions. These APIs integrate with the scraping scripts and manage proxy ip rotations, request handling, and error management automatically. Here’s a step-by-step guide on how to set up and use these APIs for data scraping:
1. Choosing the Right Residential Proxy Service
The first step in the process is selecting a reliable residential proxy provider that offers dynamic IP rotation and an API interface. It's important to choose a service that provides sufficient IP pools, high anonymity, and fast connection speeds. Many providers offer APIs designed specifically for web scraping, making it easier to integrate them with your scraping scripts.
2. API Integration and Setup
Once you've selected the right proxy service, the next step is to integrate the API with your scraping tools. Most proxy providers offer detailed documentation on how to set up the API. Generally, the integration process involves:
- API Key Setup: After registration, you will be provided with an API key that authenticates your requests.
- API Endpoint Access: The provider will give you access to specific API endpoints. These endpoints allow you to request proxies, rotate IP addresses, and monitor your usage.
You will need to incorporate the provided API key into your scraping script to authenticate and access the proxy service.
3. Proxy Rotation and Management
The core functionality of dynamic residential proxies is their ability to rotate IP addresses. When scraping large volumes of data from e-commerce websites, it’s essential to rotate proxies to avoid detection. The API handles proxy rotation automatically, ensuring that each request is sent from a different IP address.
You can configure the rotation frequency based on the volume of data you wish to scrape. Some APIs also allow you to set geographic preferences, enabling you to scrape data from specific regions or countries.
4. Making API Requests and Scraping Data
After setting up the proxies, you can start making API requests to fetch the e-commerce website data. The process typically involves sending HTTP requests (such as GET or POST) to the target website’s URL while passing through the residential proxy.
For example, the API might send a request to fetch product prices, reviews, and stock information from a product page. The data returned will be in JSON or XML format, depending on the API configuration.
5. Handling Errors and Captchas
While dynamic residential proxies significantly reduce the chances of getting blocked, websites may still deploy additional measures like CAPTCHAs or JavaScript challenges. To handle these challenges, some proxy providers offer CAPTCHA-solving services as part of their API. Alternatively, you may need to integrate CAPTCHA-solving libraries or services into your scraping workflow.
Ensuring Legal and Ethical Compliance in Data Scraping
Data scraping is a valuable tool, but it must be done ethically and legally. Many e-commerce websites have terms of service that prohibit unauthorized data scraping. Before scraping a website, it’s crucial to:
- Review the website's Terms of Service: Make sure that scraping is allowed or falls within fair use policies.
- Avoid Overloading the Server: Implement rate limits and respect the robots.txt file of the website.
- Use Data Responsibly: Ensure that the scraped data is used in compliance with privacy laws and regulations, such as GDPR.
Best Practices for Effective Data Scraping
1. Monitor Your Usage: Keep track of the number of requests made and IPs used to avoid overuse and potential blocking.
2. Use Proxies from Diverse Locations: To enhance the diversity of your scraping operation, use proxies from various countries and ISPs.
3. Adjust Scraping Frequency: Change the frequency of your requests to mimic human browsing patterns and avoid detection.
Using APIs to access dynamic residential proxy sites is an efficient and reliable method for e-commerce data scraping. By leveraging the power of rotating IPs and managing anonymity, businesses can gather valuable insights without the risk of being blocked. The key to success lies in selecting the right proxy provider, ensuring seamless API integration, and following ethical data scraping practices. When done correctly, this method opens up a wealth of opportunities for businesses to analyze market trends, monitor competitors, and enhance decision-making processes.