Your form has been submitted. We'll contact you in 24 hours.
Close
Home/Blog/How to implement multi-threaded data crawling with free residential SOCKS5 proxy?
How to implement multi-threaded data crawling with free residential SOCKS5 proxy?
PYPROXY·Jan 07, 2025
In today's digital landscape, data scraping has become an essential tool for businesses, researchers, and marketers looking to gather vast amounts of information quickly and efficiently. However, traditional methods of data scraping may encounter obstacles like IP blocking, rate-limiting, and CAPTCHAs, especially when scraping websites at scale. This is where free residential socks5 proxies come into play. By using residential proxies, scrapers can simulate real user behavior, avoid detection, and effectively bypass restrictions. When combined with multithreading, the scraping process becomes more efficient, allowing for faster data extraction across multiple threads. This article will delve into the steps and techniques required to leverage free residential SOCKS5 proxies for multithreaded data scraping, offering a comprehensive guide to maximizing your scraping efforts.
Understanding the Basics of SOCKS5 Proxies and Their Role in Data Scraping
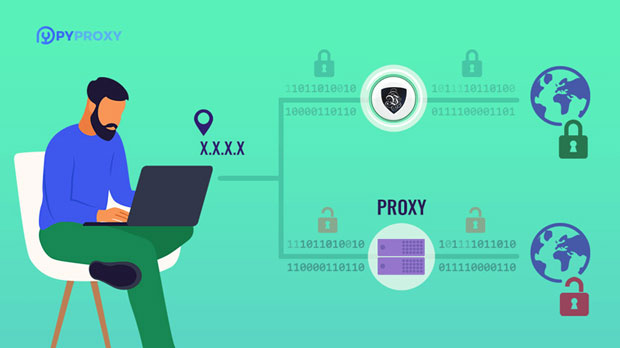
To begin, it's important to understand what SOCKS5 proxies are and why they are valuable for data scraping. SOCKS (Socket Secure) proxies are an internet protocol that allows clients to route their internet traffic through a third-party server. SOCKS5, the latest version of the protocol, provides enhanced security and supports a variety of traffic types, including HTTP, FTP, and even email protocols.
Residential proxies, specifically, are IP addresses assigned to real residential devices rather than data centers, which gives them an advantage in terms of anonymity and reliability. When using residential SOCKS5 proxies for data scraping, these proxies mimic the behavior of a real user, making it harder for websites to detect and block scraping activities. This is especially crucial when scraping large amounts of data from websites that have anti-scraping mechanisms in place.
Why Use Free Residential SOCKS5 Proxies for Data Scraping?
There are several key advantages to using free residential SOCKS5 proxies for multithreaded data scraping:
1. Avoiding IP Bans: Websites are more likely to block IP addresses that repeatedly access their pages in a short period. Residential proxies are less likely to be flagged as suspicious since they are tied to real residential IP addresses.
2. Bypassing Geolocation Restrictions: Some websites may restrict access based on geographical location. Using residential proxies from different locations can help you bypass these regional restrictions.
3. Lower Risk of CAPTCHA Challenges: Websites with scraping detection mechanisms may present CAPTCHAs to challenge automated scripts. Residential IPs, especially those from diverse locations, can help reduce the frequency of CAPTCHA appearances.
4. Cost-Effectiveness: Free residential proxies, while not as reliable or fast as paid alternatives, provide a cost-effective solution for smaller-scale scraping projects where budget constraints are a concern.
Despite the advantages, it is important to remember that free proxies often come with limitations, such as slower speeds, limited bandwidth, and reliability issues. These challenges must be taken into account when planning large-scale data scraping tasks.
Setting Up Multithreaded Data Scraping Using SOCKS5 Proxies
Once you've chosen your proxies, setting up a multithreaded data scraping process requires a few essential steps to ensure efficiency and success. Below is an overview of the process:
1. Choose a Scraping Framework or Library:
To facilitate multithreaded scraping, you'll need a tool or library that supports multithreading and can handle proxies. Popular scraping libraries, such as Python’s Scrapy or BeautifulSoup, can be configured to work with SOCKS5 proxies. Many of these libraries provide built-in support for proxy rotation, which is essential when using free proxies.
2. Configure Proxy Rotation:
Free residential SOCKS5 proxies often come with limited usage time or data transfer limits. To prevent overusing a single proxy, configure your scraper to rotate proxies periodically. This ensures that the same IP is not being overused, which could trigger rate limits or bans.
- Proxy Pool: Maintain a pool of proxies to rotate through during the scraping process. The larger the pool, the more effectively you can avoid detection.
- Proxy Rotation Libraries: Use libraries or middleware that can automatically rotate proxies after each request or after a specified number of requests.
3. Implement Multithreading:
Multithreading allows your scraping bot to perform multiple tasks simultaneously, significantly speeding up the data collection process. In Python, libraries like `threading` or `concurrent.futures` can be used to implement multithreading. Each thread should handle a different proxy and scrape a unique target page.
- Thread Pooling: Use thread pooling techniques to limit the number of threads active at any given time, preventing your system from becoming overwhelmed.
- Task Distribution: Divide the target scraping tasks among the threads, ensuring that each thread handles different requests and interacts with different proxies.
4. Error Handling and Retries:
Since free proxies are often unreliable, it’s essential to implement error handling mechanisms to ensure smooth scraping. If a proxy is blocked or returns an error, your bot should automatically retry the request with a different proxy.
- Timeouts and Retries: Set timeouts to avoid hanging on slow or unresponsive proxies, and implement retry logic to attempt failed requests with another proxy.
5. Rate Limiting and Politeness:
Even though residential proxies help bypass rate limits, it's still important to mimic human browsing behavior to avoid overloading the target website. Introduce random delays between requests and adjust the scraping speed based on the website's response time.
Challenges and Considerations When Using Free Residential SOCKS5 Proxies
While free residential SOCKS5 proxies provide a viable solution for data scraping, they are not without their drawbacks. The following challenges should be considered:
1. Limited Proxy Pool Size:
Free proxies often come with a small pool of IPs, which can lead to faster detection and blocking. A small pool increases the risk of your proxies being blacklisted if they are repeatedly used for scraping.
2. Slower Speeds and Latency:
Free residential proxies may suffer from slower speeds due to congestion or high demand. This can lead to delays in the scraping process, especially when working with large datasets.
3. Reliability:
Free proxies are less reliable than paid options. They may go offline unexpectedly, leaving your scraper unable to complete its task.
4. Legal and Ethical Issues:
It is crucial to ensure that your scraping activities comply with the target website's terms of service. Scraping content without permission can lead to legal consequences, so it’s important to scrape ethically and respect robots.txt files and other site restrictions.
Best Practices for Efficient and Ethical Data Scraping
To maximize the effectiveness of your data scraping efforts, follow these best practices:
1. Be Mindful of Website Rules: Always respect the target website’s terms of service and scraping policies. Make sure to check the robots.txt file for any restrictions on web crawlers.
2. Minimize Server Load: Spread out your requests over time, using random delays between requests to mimic human browsing activity and avoid overloading the server.
3. Use Multiple Threads with Care: While multithreading speeds up the scraping process, ensure that you do not overwhelm the website with too many simultaneous requests. Adjust the number of threads based on the website’s capacity to handle traffic.
4. Monitor and Maintain Proxy Health: Regularly check the health of your proxies. Remove inactive or blocked proxies from your pool and replace them with fresh ones.
Conclusion
Using free residential SOCKS5 proxies in combination with multithreaded data scraping offers an effective way to gather large amounts of data while circumventing detection mechanisms. By carefully selecting and managing your proxies, setting up multithreading properly, and addressing common challenges, you can enhance the efficiency and scalability of your scraping operations. While free proxies come with certain limitations, they can still serve as a valuable tool for smaller scraping tasks, provided that they are used judiciously and responsibly.