Your form has been submitted. We'll contact you in 24 hours.
Close
Home/Blog/How to combine Proxy Scraper DuckDuckGo and Pyproxy to improve Web Scraping success?
How to combine Proxy Scraper DuckDuckGo and Pyproxy to improve Web Scraping success?
PYPROXY·Apr 01, 2025
Web scraping is a powerful tool for extracting valuable data from websites, but the process can be challenging due to website defenses such as IP blocking, CAPTCHA verification, and rate-limiting. Combining Proxy Scraper, DuckDuckGo, and PYPROXY offers a strategic solution to bypass these obstacles and significantly improve the success rate of web scraping. This combination enhances anonymity, reduces the risk of detection, and allows for a more efficient scraping process. In this article, we will explore how using Proxy Scraper, DuckDuckGo, and Pyproxy together can optimize your web scraping efforts and help overcome common challenges.
Understanding the Basics: What is Web Scraping?
Web scraping refers to the automated process of extracting data from websites using a web crawler or script. While this process can be highly useful for gathering large amounts of data, it can also come with many technical challenges. For example, websites often deploy various anti-scraping mechanisms to prevent their content from being harvested. These mechanisms can include IP address blocking, CAPTCHA tests, and user-agent monitoring, all of which can make scraping operations difficult.
To address these challenges, a combination of tools like Proxy Scraper, DuckDuckGo, and Pyproxy can be used. Let's break down how each of these tools plays a crucial role in increasing the success rate of web scraping.
The Role of Proxy Scraper in Web Scraping
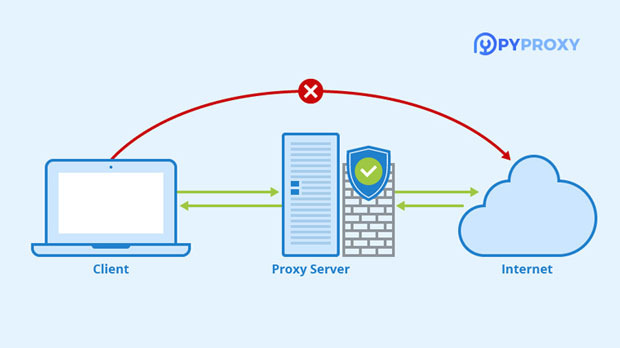
Proxies are an essential component in web scraping because they help hide the identity of the scraper by routing requests through different IP addresses. This is particularly useful when scraping multiple pages from a website, as it reduces the chances of getting blocked for making too many requests from the same IP address.
Proxy Scrapers are tools specifically designed to collect a large pool of proxies. They continuously harvest proxies from various sources, such as public proxy lists, private networks, and paid proxy services. By using a proxy scraper, scrapers can gather a wide range of IP addresses, which can then be used in their scraping process to distribute the requests across multiple IPs.
Using a diverse set of proxies ensures that the scraper doesn't overload any single IP address with too many requests, thus reducing the likelihood of detection and blocking by websites. The more proxies you have at your disposal, the more requests you can send to websites without triggering anti-scraping defenses.
How DuckDuckGo Enhances Anonymity in Web Scraping
DuckDuckGo is a privacy-focused search engine that does not track or profile users. While web scraping tools typically rely on browsers or search engines to identify URLs or gather data, DuckDuckGo offers an important advantage: it does not store user information or track IP addresses.
For web scrapers, this means that DuckDuckGo can be used as an anonymous search tool to gather links or scrape data without worrying about the usual risks of being tracked by search engines or websites. Traditional search engines may block or restrict scrapers by tracking their activity across sessions. With DuckDuckGo, scrapers can remain undetected and reduce the chances of IP bans or CAPTCHA challenges.
Furthermore, DuckDuckGo's ability to present unbiased search results can be valuable when scraping data from websites that are aggregated or indexed through search engines. This can improve the accuracy and relevancy of the data being scraped.
Using Pyproxy for Proxy Management and Rotating IPs
Pyproxy is a Python library designed to manage and rotate proxies efficiently during web scraping tasks. One of the challenges faced by scrapers is the need to continuously rotate proxies to avoid detection. Many websites track IP addresses and employ mechanisms that detect scraping behavior. If a single IP address makes too many requests in a short amount of time, it can quickly become flagged, leading to a block.
Pyproxy helps automate the process of rotating proxies. It integrates with Proxy Scrapers and ensures that each request is sent from a different proxy ip, mimicking the behavior of multiple users browsing the website. This makes it significantly harder for websites to detect that the traffic is coming from a scraper, thereby increasing the success rate of the operation.
In addition to rotating proxies, Pyproxy offers tools to manage proxy pools, handle errors related to proxies, and track proxy performance. This ensures that scrapers can easily switch to a working proxy if one becomes blocked, without interrupting the scraping process.
Combining Proxy Scraper, DuckDuckGo, and Pyproxy for Optimal Results
When you combine Proxy Scraper, DuckDuckGo, and Pyproxy in your web scraping strategy, the result is a highly efficient and effective scraping setup. Here’s how these tools work together to improve the success rate:
1. Proxy Scraper: The first step is to gather a wide range of proxies using a Proxy Scraper. This will provide you with a pool of IP addresses that can be rotated throughout the scraping process.
2. DuckDuckGo: As you gather data or scrape URLs, use DuckDuckGo as the search engine of choice. This will ensure your actions remain anonymous, reducing the likelihood of being flagged by search engines or websites for scraping.
3. Pyproxy: Once you have the proxies and have collected the necessary URLs or data, use Pyproxy to rotate and manage the proxies during the scraping process. This will allow you to send requests from multiple IP addresses, ensuring that your requests appear to come from different users, thus minimizing the chances of detection and blocking.
Benefits of Using Proxy Scraper, DuckDuckGo, and Pyproxy Together
By combining these tools, you can enjoy several key benefits that will improve your web scraping success rate:
- Anonymity: DuckDuckGo provides privacy, and Proxy Scraper ensures you have a diverse range of proxies, both of which help keep your scraping activity hidden from websites and search engines.
- Reduced Blockages: The use of multiple proxies and IP rotation reduces the likelihood of your IP being blocked, as requests are distributed across a wide range of IPs.
- Efficiency: Pyproxy automates proxy rotation, saving time and effort. It also ensures a smoother scraping experience by allowing for continuous scraping without interruptions due to proxy issues.
- Improved Data Accuracy: The combination of DuckDuckGo's unbiased search results and diverse proxies ensures that the data collected is both accurate and reliable, with minimal risk of getting blocked during the scraping process.
Incorporating Proxy Scraper, DuckDuckGo, and Pyproxy into your web scraping setup provides a robust and efficient approach to overcoming common obstacles such as IP blocking and CAPTCHA verification. By using Proxy Scraper to gather a range of proxies, DuckDuckGo for anonymous search, and Pyproxy to manage proxy rotation, you can significantly increase the success rate of your scraping operations. This combination not only ensures anonymity and reduces the risk of detection but also improves the overall efficiency of the scraping process, making it a highly valuable strategy for anyone looking to perform web scraping on a larger scale.