Your form has been submitted. We'll contact you in 24 hours.
Close
Home/Blog/Crawler essential, how to use IP proxies to break through the anti-climbing mechanism?
Crawler essential, how to use IP proxies to break through the anti-climbing mechanism?
Author:PYPROXY
2025-01-22
In today's online environment, web scraping technology has become an essential tool for data collection and information analysis. However, as anti-scraping mechanisms have become increasingly sophisticated, overcoming these obstacles has become a critical challenge for web scraping developers. ip proxies, as an effective technical means, can help bypass these protective measures and ensure successful data extraction. This article will delve into how to use IP proxies to overcome anti-scraping mechanisms and improve the efficiency and success rate of web scraping.
What Are IP Proxies and How Do They Work?
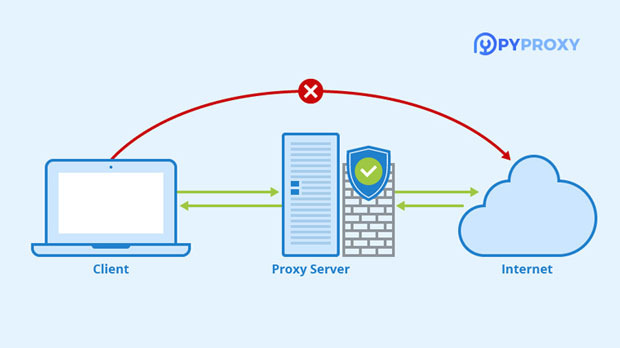
IP proxies refer to intermediary servers that replace the real user's IP address for online access. The basic principle of how they work is that when a user makes a request, the proxy server forwards the request to the target website, and the website only sees the proxy server's IP address rather than the user's real IP. This method helps to hide the user's true identity, protect privacy, and prevent the website from triggering anti-scraping mechanisms due to frequent access from the same IP.
The role of proxy servers is not only to mask the IP address but also to simulate different geographical locations. By using IP addresses from various regions, scrapers can bypass regional-based anti-scraping measures, making data extraction more flexible.
How Do Anti-Scraping Mechanisms Work?
Anti-scraping mechanisms are a series of protective measures taken by websites to prevent unauthorized data extraction. Common anti-scraping techniques include IP blocking, CAPTCHA challenges, and request rate limits. Websites analyze factors such as the source of requests, access frequency, and other parameters to determine whether the behavior is from a scraper and take appropriate blocking actions.
For example, when a single IP makes frequent requests to a website in a short period, the server may assume that the IP is scraping, and it may block that IP to prevent data leakage. Additionally, many websites employ CAPTCHA to prevent automated access, requiring users to enter a CAPTCHA to verify their identity.
How to Use IP Proxies to Bypass Anti-Scraping Mechanisms?
1. Use Multiple IP Pools
By using multiple IP addresses, web scrapers can effectively avoid issues related to IP blocking caused by frequent requests. A large IP pool ensures that scrapers do not repeatedly expose the same IP during data extraction, reducing the risk of being blocked. The IP addresses in the pool can be either static or dynamic, and changing IPs regularly can prevent blocks.
2. Switch IPs Dynamically
Web scrapers can dynamically switch IPs to simulate normal user behavior. For example, when an IP is blocked, the scraper can immediately switch to another IP and continue the scraping task. This method is particularly useful for long-term or large-scale data extraction tasks, as it significantly improves the success rate of scraping.
3. Set Proper Request Intervals
Too frequent requests can attract the attention of anti-scraping mechanisms. By setting appropriate request intervals, scrapers can simulate human browsing behavior and reduce the risk of being identified as a bot. Scrapers should avoid sending a large number of requests to the same website in a short period, and they can optimize the scraping process by using random intervals or simulating human browsing behavior.
4. Use High-Quality Proxies
Not all IP proxies can effectively bypass anti-scraping mechanisms. High-quality proxies usually offer better anonymity and stronger stability, ensuring that the scraper can operate efficiently. Choosing proxies with fast response times and high availability reduces the likelihood of scraping failures due to proxy quality issues.
5. Distributed Proxy Systems
A distributed proxy system involves multiple proxy nodes working together to distribute traffic. In this architecture, multiple proxy nodes collaborate to spread the scraper’s requests across different servers. This reduces the burden on each individual proxy and improves the overall stability and efficiency of the scraper. Distributed proxies are effective in preventing situations where the scraper cannot continue after a single IP is blocked.
How to Avoid Detection by Anti-Scraping Mechanisms?
1. Spoof HTTP Headers
Web scrapers can spoof HTTP request headers to make requests appear as if they come from a regular browser. By modifying fields like `User-Agent`, `Referer`, `Accept`, etc., scrapers can bypass basic anti-scraping mechanisms. Websites often use these headers to identify whether a request is from a scraper, so spoofing them is a common anti-scraping tactic.
2. Simulate User Behavior
In addition to spoofing HTTP headers, scrapers can simulate user actions, such as mouse movements or scrolling. These actions can make the website believe the traffic is coming from a human user, thus reducing the chances of being flagged as automated.
3. Use CAPTCHA Recognition Technology
Although CAPTCHA is a common anti-scraping measure, modern CAPTCHA recognition technology has become more advanced. Scrapers can integrate CAPTCHA solving modules to automatically handle CAPTCHAs, ensuring the scraping process isn't interrupted.
Choosing the right IP proxy service is crucial for bypassing anti-scraping mechanisms. First, the quality of the proxies is essential; low-quality proxies may cause frequent disconnections or slow speeds, affecting scraper performance. Second, choose a proxy service that offers a large pool of IP addresses, providing a variety of IP options to reduce the risk of blocking.
Moreover, stability and response speed are important considerations. Stable proxies ensure the scraper can run continuously, while fast proxies improve scraping speed and efficiency. Lastly, depending on the scraping needs, it’s important to choose the right type of proxy, such as data center IPs, residential IPs, or mobile IPs, as different proxy types are suited to different scraping scenarios.
Conclusion
IP proxies play a critical role in bypassing anti-scraping mechanisms. By using IP proxies effectively, scrapers can avoid IP blocking, CAPTCHA challenges, and other anti-scraping measures, ensuring smooth data extraction. Scraper developers must choose the appropriate IP pools, proxy types, and proxy services based on their needs and employ effective techniques such as spoofing headers and simulating user behavior to improve scraping success rates. Ultimately, successful data scraping depends not only on the quality of the IP proxies but also on the application of various anti-scraping techniques and strategies.